

2023년 3월 14일, 인공지능 세계는 또 다시 한 걸음 발전했습니다. ChatGPT로 전 세계에 생성형 AI (Generative AI) 열풍을 일으킨 인공지능 업체 OpenAI가 이번에는 새로운 대규모 인공지능 언어 모델(LLM) GPT-4를 공개했다고 합니다.
Chat-3.5 시리즈의 한 모델이자 현 시대 인공지능 끝판왕이라 불리던 ChatGPT를 또 한 번 업그레이드했는데요. 이처럼 똑똑한 지성체같은 GPT의 뿌리는 사실 “인간에 의해 엄청나게 많이 학습된 데이터”라는 것을 알고 계셨나요? 좋은 AI를 만들기 위해서는 결국 좋은 데이터를 넣어야 한다는 것입니다.

이번 글에서는 AI에서 기술보다 데이터가 더 중요한 이유를, 그리고 좋은 데이터를 얻는 방법에 대해 셀렉트스타가 소개한 아티클을 엮어 알려드려보고자 합니다. 해당 내용은 2021 오픈데이터셋 컨퍼런스 “좋은 인공지능을 위한 데이터 준비”를 축약하였습니다.
인공지능의 생명력을 불어 넣어주는 좋은 데이터, 학습 데이터
인공지능은 사람이 작업한 데이터를 보고 따라하면서 지능을 얻습니다. 여기서 사람이 작업한 데이터를 우리는 인공지능의 학습 데이터라 일컫습니다.
인공지능과 그 생명력을 불어넣어주는 학습 데이터는 우리의 일상생활 속 곳곳에 자리매김하고 있습니다.

학습 데이터 없이는 인공지능을 개발할 수 없고, 양질의 데이터가 없으면 더더욱 좋은 인공지능을 개발할 수 없다.
좋은 데이터를 수집하고 가공하는 것이 AI를 만드는 과정의 80%를 차지합니다. 이는 데이터가 인공지능의 Core Part임을 의미합니다.
- by Andrew Ng, co-founder of Landing AI (세계적 인공지능 석학)
기존에는 AI개발에 대한 고민을 하는 시대였다면, 지금은 학습데이터를 어떻게 만들까 라는 고민이 더 중요해지는 시대가 도래했습니다.
좋은 데이터의 기준
셀렉트스타 김세엽 대표는 ‘좋은 데이터’의 기준을 다음 4가지로 정의했습니다.
Accuracy (정확성) : 의도에 맞는 정확한 데이터
Consistency (일관성) : 일관된 레이블링 결과
Coverage (커버리지) : 다양한 데이터와 충분한 케이스 스터디
Balance (편향성) : 편향되지 않고 고르게 구성된 데이터
기준 1. Accuracy
의도에 맞는 정확한 데이터 : 가이드 라인에 위배되는 데이터가 없게 하는 것이 관건입니다.

Key Point 1. 가독성 높은 가이드라인
사용자에게 초점을 맞춰 최대한 전문용어를 지양하고 ‘쉬운 용어’로 작성하여 효과적인 가이드를 구성해야 합니다.
Key Point 2. 더욱 정확한 결과 도출을 위한 작업 전 테스트 수행
가이드라인에 맞는 고단이도 테스트를 구성하여 통과한 작업자만이 작업에 참여할 수 있게 하여, 더욱 높은 데이터 퀄리티를 보장하는 것이 필요합니다.
Key Point 3. 전문가들의 정확한 검수!
숙련된 작업자 + 인하우스 검수자들이 ‘교차검수’를 통해 더욱 정확하게 필터링하는 작업도 중요합니다. 셀렉트스타는 검수자의 정확도 및 집중력의 의존도가 큰 단일 검수 방식이 아닌 신뢰도를 가중치로 반영해 교차 검수 결과를 결정 다수결 교차 검수 방식을 채택하여 일반적인 단일/다수결 검수보다 더 정확한 검수가 이루어지도록 설계했으며, 이는 국내외 주요 플랫폼 중 유일합니다.
기준 2. Consistency
일관된 레이블링 결과 데이터 : 작업자에 무관하게 동일한 레이블링 작업 시 그 결과가 일관되어야 합니다.
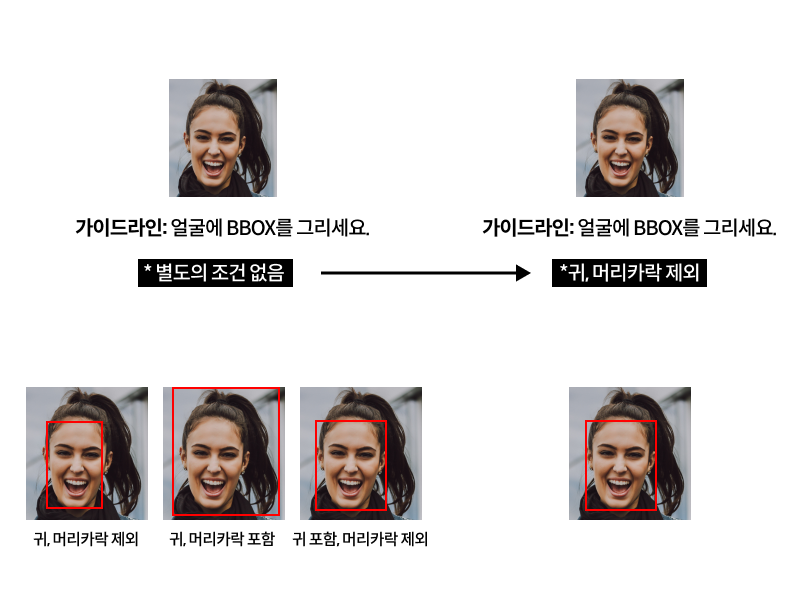 Key Point. 작업의 주관성을 최대한 배제한 ‘작업원칙’ 수립!
Key Point. 작업의 주관성을 최대한 배제한 ‘작업원칙’ 수립!
주관적인 부분을 최대한 객관화하여 일관된 레이블링 결과를 도출하도록 설계해야 합니다.
음성이나 감정 등 주관적인 부분을 최대한 객관화할 수 있도록, 보다 정확하고 이해가 쉬운 가이드라인을 수립하고 유저들의 일관된 작업을 확보하기 위해 노력을 기울여야 합니다.
기준 3. Coverage
다양한 데이터와 충분한 케이스 스터디 : 서비스 운영 상황에 맞춰 데이터를 최신화해야 한다.
음성인식용 데이터셋의 경우 학습 데이터에 적거나 없었던 신조어, 유행어 등에 맞춰 데이터를 최신화하는 것처럼, AI운영 상황을 고려하여 수집 시나리오를 정하고 가능한 한 다양한 데이터를 수집하여 ‘Coverage’ 를 넓혀야 합니다.

특히 Coverage를 더욱 높이기 위해 AI가 마주할 수 있는 다양한 케이스의 데이터를 충분하게 만들어 주는 것이 관건입니다.
셀렉트스타의 ‘얼굴 데이터셋’ 수집 시나리오를 예시로 들어 본다면, 1,100여 명의 유저를 모아 3개의 조명 조건(실내 조명, 실외 자연광, 어두움), 8개의 상황조건(마스크 착용, 코스크 착용, 턱스크 착용 등), 11개의 각도 조건(정면, 오른쪽 22.5º, 오른쪽 45º. 오른쪽 90º 등)을 만들어 총 264개의 경우의 수를 모아 데이터를 구축하였습니다.

데이터를 수집하다 보면 유사한 데이터를 제출하는 경우가 상당히 많은데, 최대한 다양한 데이터를 모으는 것이 중요한 것이기 때문에 유사도가 높은 데이터는 가치가 떨어질 수 밖에 없습니다. 이 경우 일일이 사람이 수작업으로 유사도를 확인하고 필터링을 하기는 거의 불가능에 가깝습니다.
따라서 보다 다양한 데이터를 위한 유사 데이터 수집 필터링 작업이 요구됩니다.
아래의 예시와 같이 각도만 살짝 다르고 거의 동일한 사진들은 ‘유사 데이터 수집 필터링’ 기술을 통해 걸러지게 되고, 이렇게 구축된 데이터는 더욱 뛰어난 데이터로 거듭납니다.

기준 4. Balance
편향되지 않고 고르게 구성된 데이터 : 학습데이터가 고르게 구성돼야 한다.
좋은 데이터 구축을 위해서는 편향성을 없애는 것이 중요합니다.
셀렉트스타의 자동차 이상 증상 문의 텍스트 데이터를 수집했던 경험을 빗대어보면, 단순히 자동차 이상 증상 문의에 대한 텍스트를 수집했을 때, 문제가 빈번하게 일어나는 특정 경우에 대한 데이터만이 월등히 많이 수집될 것이 분명했습니다. 이러한 편향성을 최대한 줄이고자 하는 측면에서 미작동/시각/청각/촉각/후각으로 증상을 세부화하여 데이터를 수집하였습니다.
데이터 Balance를 고려한 프로젝트 설계 : 자동차 이상 증상 문의 텍스트 데이터 수집 (약 750명 참여)
미작동 : 자동차 유리창이 닫히지 않습니다.
시각 : 주행중인 차에서 ESP 경고등이 뜨네요.
청각 : 시속 50km 정도로 주행 시 차체에서 깡통소리 비슷한 소음이 발생됩니다.
촉각 : 공회전 및 차량 정차 시 차체가 심하게 떨립니다.
후각 : 에어컨 키면 퀴퀴한 냄새가 나요.
이렇게 증상에 대한 class를 세부화함으로써 한쪽으로 치우지는 편향성을 최소화하고, 원하는 퀄리티의 데이터를 구축할 수 있습니다.
From Model-centrci to Data-centric AI
위에서 언급한 노력들이 뒷받침되어야 비로소 우리는 ‘좋은 데이터’를 추출해낼 수 있습니다.
어떻게 데이터를 구축하고 파이프라인을 통한 최신화와 고도화하는 전략이 AI Flywheel의 Key입니다. Data-centric AI 관점에서 정확하고 일관된 양질의 학습데이터는 가장 높은 가치이며, 가장 중요한 것입니다.
※ 본 아티클은 “셀렉트스타”의 테크 블로그 아티클을 엮어 재편집하였습니다.
Compiled & Edited by Goody





![[사전예약] 예산 적어도 할 수 있는, 저예산 고효율 스타트업 '마케팅 실무' 9기](/_next/image?url=https%3A%2F%2Fgrownbetter-prod-user-storage-upload-001.s3.amazonaws.com%2Fprogram_images%2F94dea5a5-6842-416e-b6be-e3998db08ee5&w=3840&q=75)

